
This blog post author Remigijus works in Visma IT & Communications team as a Cloud Engineer. He is a software technology enthusiast. Meanwhile, IT brings in a lot of fun he also finds offroad motorcycle is a good way to clear minds and helps to keep „work and life“ in balance.
I’ve joined my new team recently and it is quite a luck to start at a great moment – phase of moving workloads from traditional Virtual Machines to a nice combination of Serverless framework and a bunch of AWS services like API GW, Lambda, Fargate and many more to run the solution. What makes this so intriguing?
Reasoning
– pay as you go. Some of our workloads are relatively demanding for computing power: 15-180 minutes of intense heuristics. On the other hand, processing is required on a period basis only.
Data processing algorithms return initial results quite fast, meanwhile, each next calculation cycle gives more and more precise outcomes, however, this comes with a cost of time: each next cycle of calculation takes longer to complete compared to the previous iteration. So, at any moment customers can accept the current result as an eligible one therefore halting further processing.
We believe our existing setup utilizing large and expensive EC2 instances doing nothing most of the time is not the most cost-effective option.
– scalability. Our current architecture allows us to run 5 workloads per machine concurrently. With the current amount of customers/visitors requests are fulfilled with no delays. However, forecasts of service growth demands to be ready to serve 200 jobs simultaneously, which, according to our current design is 40 virtual machines at a minimum. Leaving costs alone, it’s also a technical challenge to configure auto-scaling, deal with “cold starts”, keep AMI patched up to date, etc…
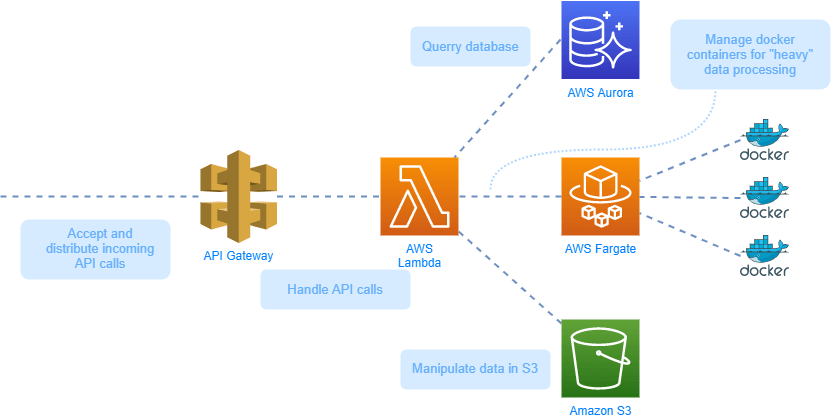
Architecture
Components
- AWS API gateway: the entry point for all the incoming requests, works as a ‘proxy’ between external service (requestor) and Lambda functions
- AWS Lambda: to handle requests directing from API Gateway
- Docker containers on AWS Fargate for “heavy” data processing
- Elastic Container Registry, IAM, CloudWatch, S3, Aurora database to run and support our services
- Infrastructure components defined with Terraform
- Serverless framework for easier Lambda’s deployment
Future work
Is it something new? No, within Visma group we already have production workloads configured in similar fashion.
Will it work for our use case? Yes, it will.
Will it meet our expectations – time will tell. 🙂
We already did POC at earlier stages, however, refactoring part of a service will also be an evaluation if such setup can be defined as a ‘blueprint’ aiming to apply the same principles on other units of our service.
Nevertheless, main building blocks and flows are defined, still there are a number of missing pieces to complete picture fully, so our plans for coming months are to address:
- Observability – we think central logging is a must to make “our lives easier” during troubleshooting
- Observability – with CloudWatch running Out Of the Box, we think we could benefit utilizing Grafana / Loki
- CI/CD pipelines are still in a progress to its final “shape” with rollout/release strategy being defined


